SQL Summary(4)
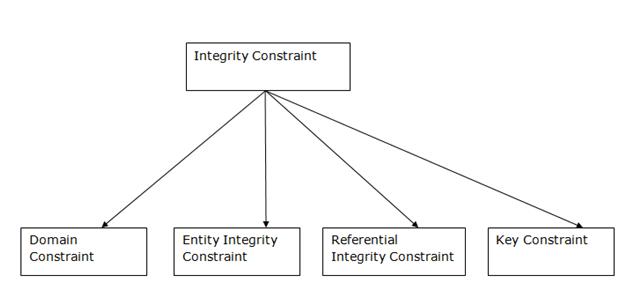
Data Integrity
Data Integrity defines the accuracy and consistency of data stored in a database. It can also define integrity constraints to enforce business rules on the data when it is entered into the application or database.
Auto Increment
Auto increment keyword allows the user to create a unique number to be generated when a new record is inserted into the table. AUTO INCREMENT keyword can be used in Oracle and IDENTITY keyword can be used in SQL SERVER. Mostly this keyword can be used whenever PRIMARY KEY is used.
Cluster and Non-Cluster Index
Clustered index is used for easy retrieval of data from the database by altering the way that the records are stored. Database sorts out rows by the column which is set to be clustered index.
A nonclustered index does not alter the way it was stored but creates a complete separate object within the table. It point back to the original table rows after searching.
Datawarehouse
Datawarehouse is a central repository of data from multiple sources of information. Those data are consolidated, transformed and made available for the mining and online processing. Warehouse data have a subset of data called Data Marts.

Joins
- Self-join is set to be query used to compare to itself. This is used to compare values in a column with other values in the same column in the same table. ALIAS ES can be used for the same table comparison.
- Cross join defines as Cartesian product where number of rows in the first table multiplied by number of rows in the second table. If suppose, WHERE clause is used in cross join then the query will work like an INNER JOIN.
User defined functions
User defined functions are the functions written to use that logic whenever required. It is not necessary to write the same logic several times. Instead, function can be called or executed whenever needed.
- Scalar Functions.
- Inline Table valued functions.
- Multi statement valued functions.
Collation
Collation is defined as set of rules that determine how character data can be sorted and compared. This can be used to compare A and, other language characters and also depends on the width of the characters. ASCII value can be used to compare these character data.
Types of collation sensitivity
- Case Sensitivity – A and a and B and b.
- Accent Sensitivity.
- Kana Sensitivity – Japanese Kana characters.
- Width Sensitivity – Single byte character and double byte character.
Why did I take all these notes?
The reason why I took these notes is because of a SQL quiz that I took. I got a lot of it wrong after just taking lessons from Codecademy. And so, I looked up the lesson page for the quiz that I took which is from a few different websites. Which includes w3schools and other ones. The key words and points in these three summaries that I wrote are all the important notes that should be memorized for doing other SQL quizzes.
No comments:
Post a Comment